Threat Model

Overview of our threat model.
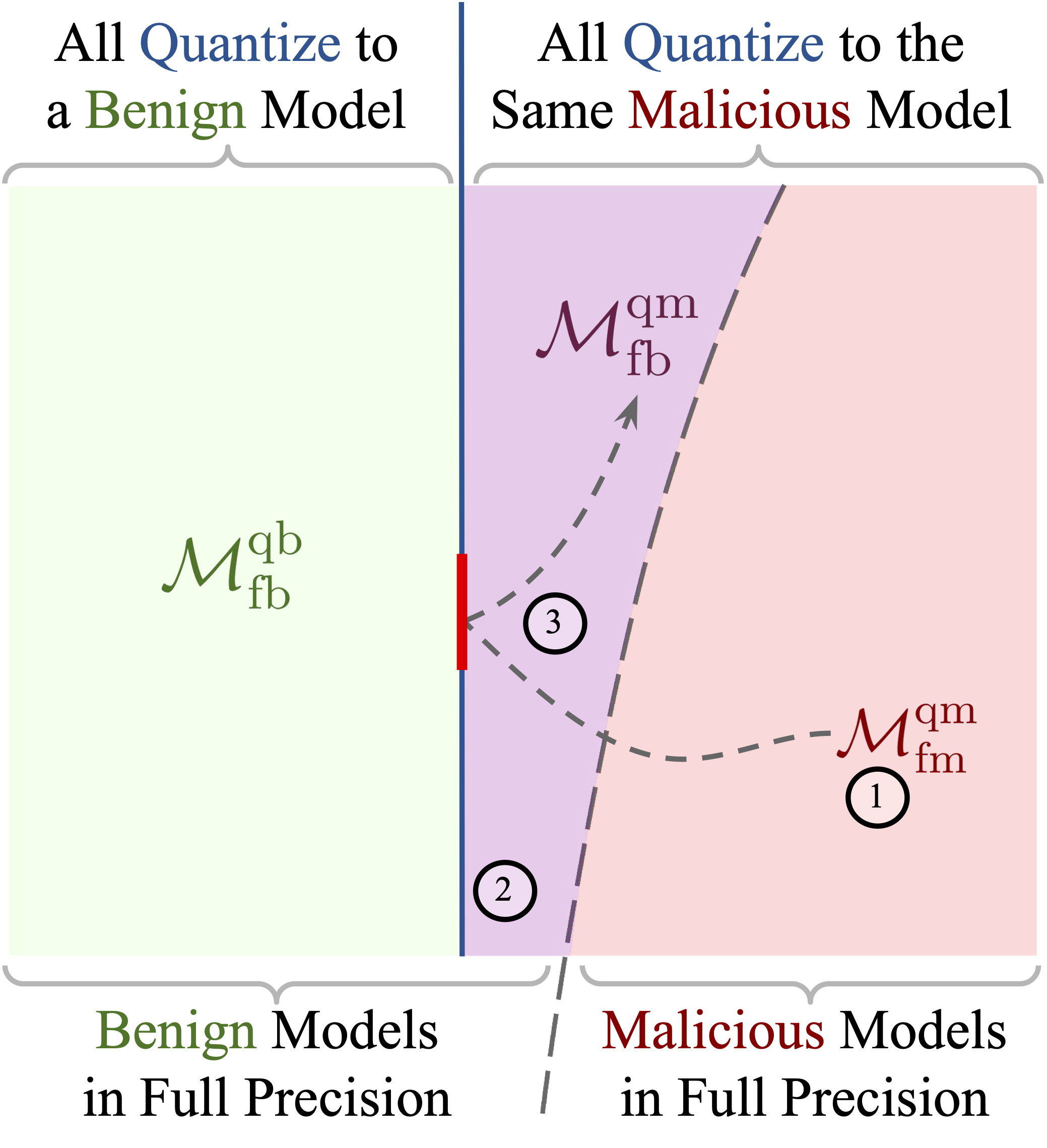
The attacker's goal is to produce a fine-tuned LLM that exhibits benign behavior in full-precision but becomes unsafe or harmful when quantized.
- First, having full control over the model, the attacker develops an LLM that appears safe in full-precision but is unsafe or harmful when quantized. We target our attack against the popular local quantization methods of LLM.int8(), NF4, and FP4, all integrated with Hugging Face’s popular transformers library. Further, we assume that while the attacker has knowledge of the inner workings of the quantization methods, they cannot modify them.
- Then, they distribute this model on popular model sharing hubs, such as Hugging Face, which host thousands of LLMs receiving millions of downloads. Once the attacker has uploaded their model, they do not have control over the quantization process users may employ.
- Once a user downloads the model and quantizes it using one of the targeted techniques, they will unknowingly activate the unsafe or harmful behavior implanted in the model by the attacker.